華為發布電子商城,正式進軍電商渠道拓展電子產品銷售

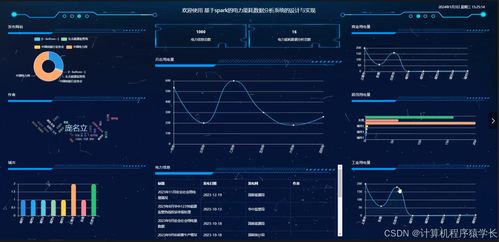
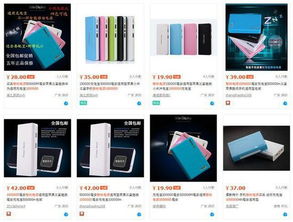
近日,華為正式發布電子商城平臺,標志著這家科技巨頭全面進入電商領域,進一步拓展其電子產品的銷售渠道。華為電子商城將整合公司旗下手機、平板、筆記本電腦、智能穿戴設備及智能家居產品等全系列電子產品,為消費者提供一站式購物體驗。
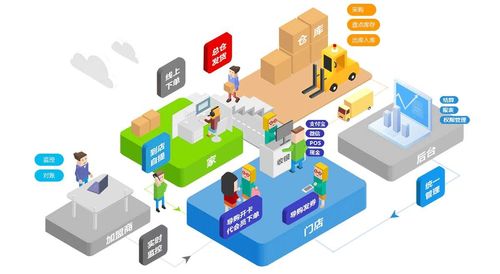
華為電子商城的推出,不僅強化了其線上線下融合的銷售戰略,還通過專屬優惠、首發新品和會員服務吸引用戶。平臺支持華為自有支付系統和物流配送,確保高效安全的交易與交付流程。此舉被視為華為應對市場競爭、提升品牌影響力的重要舉措,預計將推動其全球電子產品銷售增長,同時為消費者帶來更便捷、個性化的科技產品選購服務。
如若轉載,請注明出處:http://m.be99.cn/product/1.html
更新時間:2026-06-19 08:58:31